From my keynote talk at the Cambridge Wireless event:
‘Delivering Big Data: Practical solutions with an emphasis on open source’ – Big Data SIG event – London – 23 April 2015
The slides are now available from the CW website
While giving an overview of the tooling available, I presented questions that should be considered in selecting tools for Big Data projects:
Where is the area of difficulty? ‘Traditional’ tools such as Excel may be quite adequate for a quick look at a sample of data, or familiar tools such as R may allow domain experts to model data and devise processing algorithms more quickly.
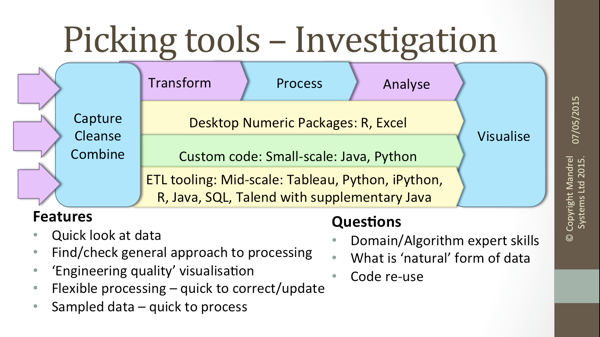
How fast will data be received, and how much will there be? This will determine whether tools such as Hadoop are needed.
How soon will processed results be needed? If this a genuine streamed application, Storm should be considered, but often, what is initially thought of as a streaming project is simply a data capture problem, with a ‘fast batch’ processing chain.
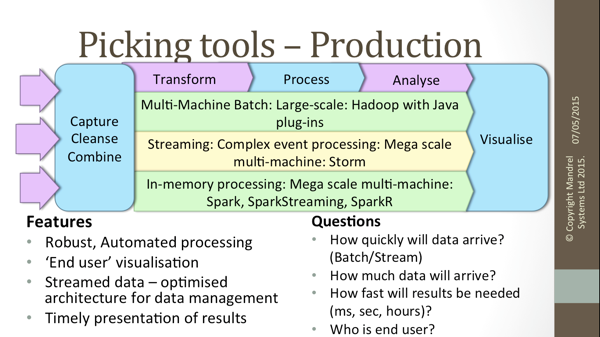
Different tooling may well be used at investigation and production stages. While re-use is desirable, it may sometimes be better to use the best tool for each stage, making a clean start into production after the task is clearly defined.
